Building a Self-Sustaining Efficiency Engine: A Hyperscale Guide to AI-Powered Performance Optimization
Introduction
At Meta, optimizing capacity efficiency at hyperscale requires a systematic approach that balances proactive optimization (offense) and rapid regression mitigation (defense). By encoding domain expertise from senior engineers into AI agents, we have created a unified platform that automates both finding and fixing performance issues. This step-by-step guide outlines how you can replicate this approach to recover hundreds of megawatts of power, reduce manual investigation time from hours to minutes, and scale efficiency without proportionally increasing headcount.

What You Need
- Large-scale infrastructure handling billions of requests daily (e.g., data centers, servers, network equipment).
- Senior efficiency engineers with deep knowledge of performance bottlenecks and remediation strategies.
- AI/ML platform capable of running agents, storing skills, and orchestrating workflows.
- Regression detection tool (similar to Meta’s FBDetect) to catch production performance regressions automatically.
- Unified tool interface that standardizes how different systems (monitoring, code review, deployment) communicate.
- CI/CD pipeline to deploy both code changes and AI agent updates.
- Codified best practices from past efficiency wins and common failure patterns.
Step 1: Define Your Efficiency Strategy – Offense and Defense
Offense means proactively searching for optimization opportunities in existing systems (e.g., code refactoring, algorithm improvements) and deploying them. Defense means monitoring production resource usage to detect regressions, root‑cause them to specific pull requests, and deploy mitigations. Both are essential. Document key metrics (power usage, latency, throughput) and set targets for power recovery per quarter.
Step 2: Build a Unified AI Agent Platform
Create a platform that abstracts the complexity of back‑end systems. This platform should expose a standardized interface for agents to query logs, performance counters, deployment history, and code repositories. All agents communicate through this common layer, enabling composability. Implement security and permission controls so agents only access data relevant to their tasks.
Step 3: Encode Domain Expertise into Reusable Skills
Work with senior efficiency engineers to capture their decision‑making process. Decompose typical investigation workflows (e.g., “identify top resource consumers”, “check recent deploy changes”, “suggest code refactor”) into discrete, reusable skills. Store these skills as code (e.g., Python functions) in the platform. Use version control and testing so that human‑engineered improvements propagate to all agents.
Step 4: Automate Regression Detection
Deploy a regression detection system (e.g., FBDetect) that continuously monitors fleet‑wide performance metrics. When a significant regression is detected, it should automatically file a ticket with relevant details (time, metric change, candidate pull requests). The system must be tuned to minimize false positives while catching regressions within hours. Integrate this tool with the AI agent platform so that tickets trigger automated investigation.
Step 5: Automate Diagnosis and Fixing with AI Agents
Configure AI agents to receive regression tickets and execute skills step‑by‑step. For defense: agents correlate the regression with recent code changes, run A/B comparisons, and generate a root‑cause report within ~30 minutes (instead of ~10 hours manually). For offense: agents scan large codebases for patterns that match known optimization opportunities, produce a pull request with code changes, and request human review. Each agent records its reasoning for transparency.
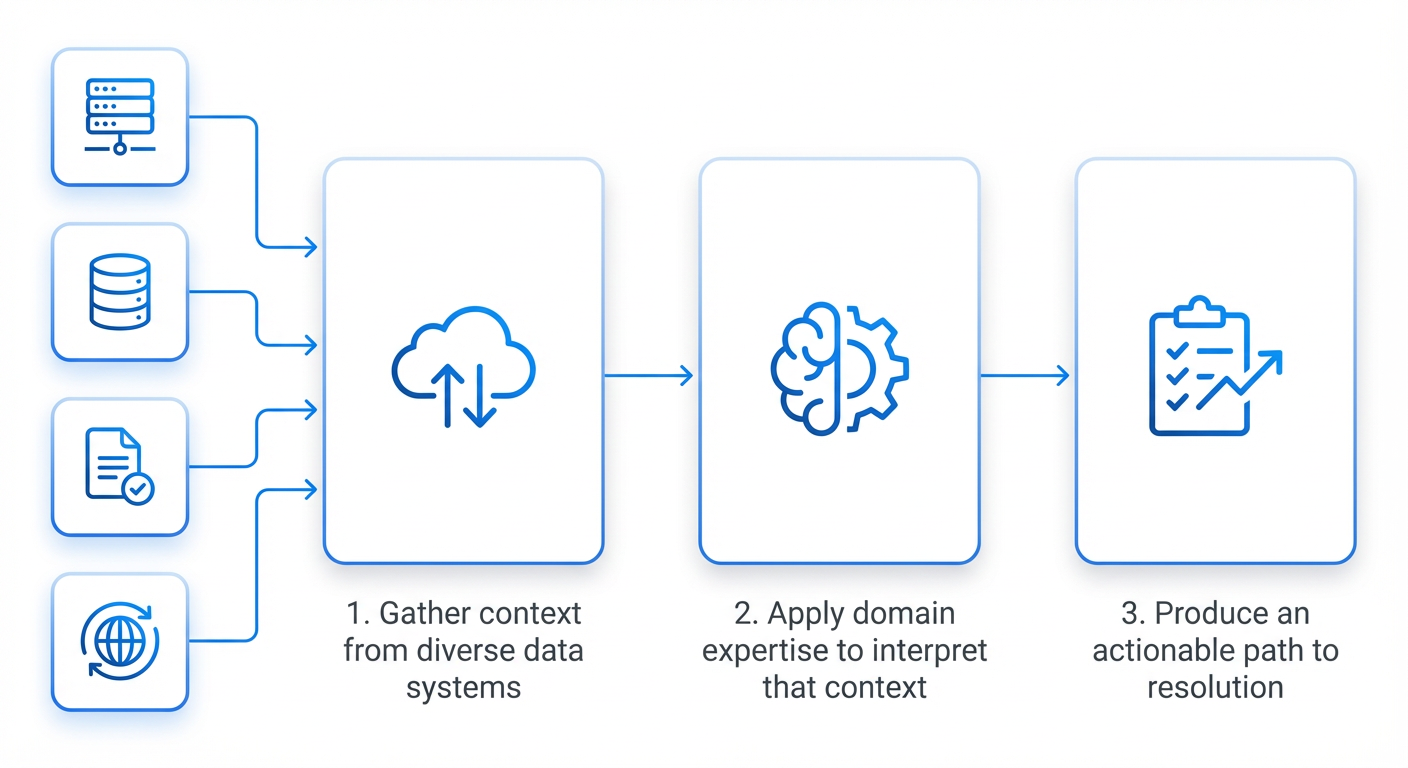
Source: engineering.fb.com Step 6: Scale MW Recovery and Decrease Manual Effort
Roll out agents to more product areas each half. Track two key metrics: total megawatts (MW) recovered and ratio of engineer hours spent per MW saved. The goal is to increase MW delivery without growing the team proportionally. For example, Meta recovered hundreds of MW – enough to power hundreds of thousands of homes. Use automated reporting to share success stories, which builds trust and encourages wider adoption.
Step 7: Aim for a Self‑Sustaining Engine
Continuously improve agent skills by feeding back learnings from past wins. Implement a feedback loop: when a human engineer modifies an agent‑generated pull request, the changes should be encoded as a new skill or an update to an existing one. Over time, the platform handles an increasing share of the “long tail” of efficiency opportunities, freeing engineers to focus on strategic innovation. This creates a virtuous cycle where AI becomes the primary executor of routine efficiency work.
Tips for Success
- Start with a pilot team that has the highest density of senior expertise. Validate that agents can replicate their decisions before expanding.
- Invest in logging and observability for the agents themselves. You need to know why an agent chose a particular fix, especially when it fails.
- Regularly refresh encoded skills as infrastructure evolves. Schedule quarterly reviews of agent performance and update skills accordingly.
- Celebrate wins publicly within the organization. Show how many engineer hours were saved and how many MW were recovered to motivate broader adoption.
- Balance automation with human oversight for high‑risk changes. Critical infrastructure changes should still require human approval until agents prove reliability.
- Use internal anchor links (like Step 1) in dashboards to let engineers quickly jump to relevant sections of this guide.