How Meta's AI Pre-Compiler Unlocks Hidden Code Knowledge for Engineering Teams
Introduction: The Limits of AI Without Context
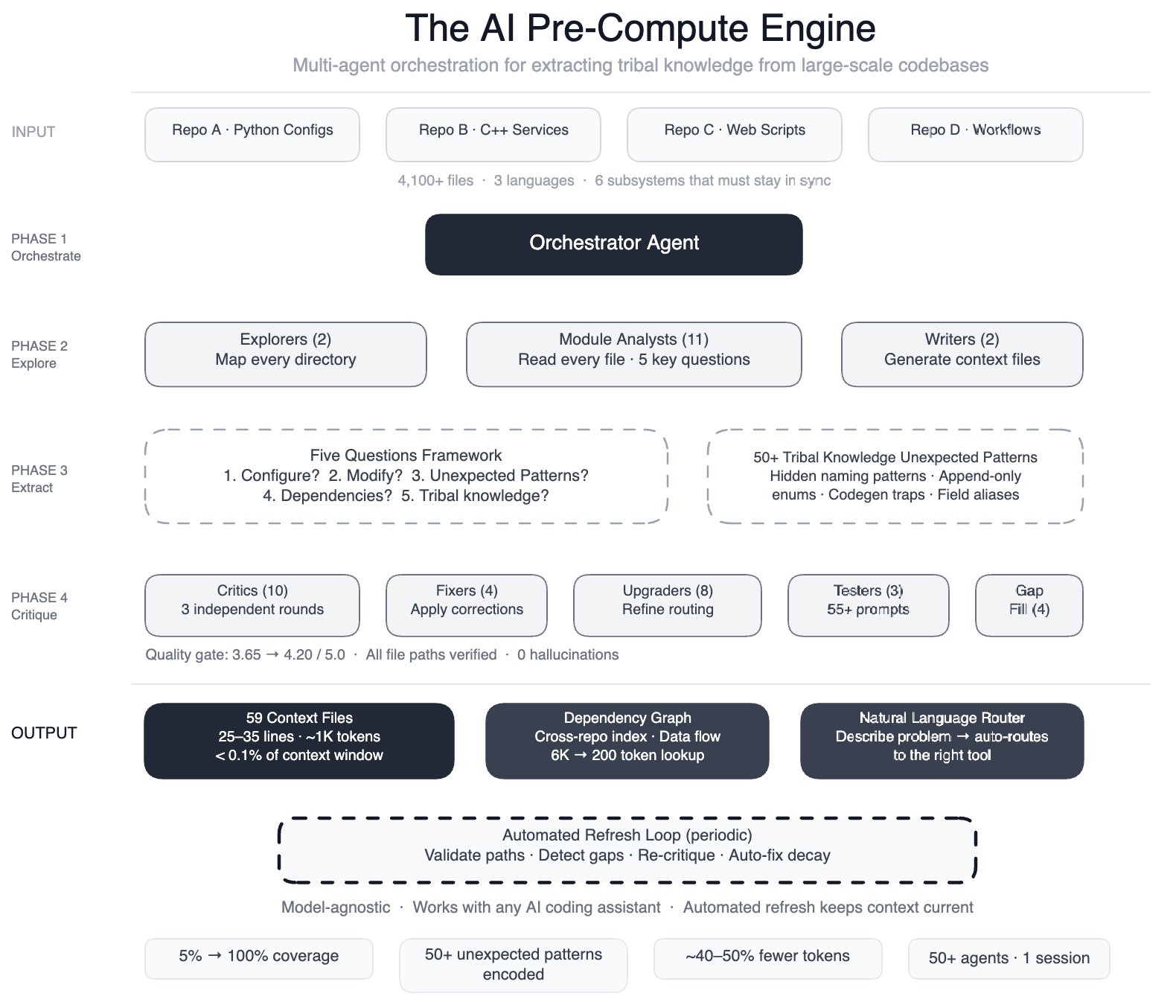
AI coding assistants have become powerful tools, but their effectiveness hinges on how well they grasp the underlying codebase. When Meta directed its AI agents at one of its massive data processing pipelines—spanning four repositories, three programming languages, and over 4,100 files—the limitations became glaringly obvious. Agents struggled to make useful edits quickly, often guessing incorrectly or producing subtly flawed code. The missing piece? A structured map of the tribal knowledge that engineers carry in their heads.

The Challenge: AI Tools Without a Map
Meta's pipeline is a config-as-code system: Python configurations, C++ services, and Hack automation scripts all interoperate across multiple repositories. A single data field onboarding process touches six subsystems—configuration registries, routing logic, DAG composition, validation rules, C++ code generation, and automation scripts—that must remain perfectly synchronized.
While Meta had already built AI-powered systems for operational tasks—scanning dashboards, pattern-matching incidents, and suggesting mitigations—extending that success to development tasks was a different story. The AI lacked a map. It didn't know that two configuration modes use different field names for the same operation (swap them, and you get silent wrong output). It was unaware that dozens of “deprecated” enum values must never be removed because serialization compatibility depends on them.
Without this context, agents would guess, explore, guess again, and often produce code that compiled but was subtly wrong—a costly outcome in a large-scale environment.
The Solution: A Pre-Computer Engine of Specialized AI Agents
Meta's fix was to build a pre-compute engine: a swarm of over 50 specialized AI agents that systematically read every file in the codebase. This effort produced 59 concise context files that encode the tribal knowledge previously locked inside engineers' minds. The result: AI agents now have structured navigation guides for 100% of code modules (up from a mere 5%), covering all 4,100+ files across three repositories (the fourth was excluded for this experiment).
The system also documented 50+ “non-obvious patterns”—underlying design choices and relationships not immediately apparent from the code itself. Preliminary tests show a 40% reduction in AI agent tool calls per task, because agents no longer waste time exploring irrelevant paths. The knowledge layer is model-agnostic, meaning it works with most leading AI models without modification.
How It Works: A Multi-Phase Orchestration
Meta used a large-context-window model and task orchestration to structure the work in several phases. Each phase had a specific role, executed by distinct agent swarms:
- Explorer Agents: Two agents mapped the codebase, identifying all files and their relationships.
- Module Analysts: Eleven agents read every file and answered five key questions about its purpose, dependencies, and constraints.
- Writers: Two agents generated the 59 context files based on the analysts' findings.
- Critics: Over 10 critic passes ran three rounds of independent quality review to catch errors.
- Fixers: Four agents applied corrections to any identified issues.
- Upgraders: Eight agents refined the routing layer for better knowledge access.
- Prompt Testers: Three agents validated 55+ queries across five personas to ensure context files were useful.
- Gap-Fillers: Four agents covered remaining directories that were initially missed.
- Final Critics: Three agents ran integration tests to confirm completeness.
This orchestration happened in a single session, with over 50 specialized tasks coordinated automatically.
Results and Benefits
The impact was immediate. Coverage jumped from 5% to 100% across all targeted files. The documentation of non-obvious patterns gave AI agents crucial insights, such as which field names to use in which context, and why certain “deprecated” enums must persist. Tool call reduction of 40% means faster, more reliable AI-assisted development.
Because the knowledge layer is model-agnostic, Meta can swap AI models without rebuilding the context files. This flexibility is key for future-proofing the system.
Self-Maintaining System
The system doesn't just create context—it maintains itself. Automated jobs run every few weeks to:
- Validate file paths to ensure all referenced files still exist
- Detect coverage gaps if new files or modules are added
- Re-run quality critics to catch any degradation
- Auto-fix stale references by updating context files as the codebase evolves
In this ecosystem, the AI isn't merely a consumer of infrastructure—it is the engine that runs it.
Conclusion: AI as Engine, Not Passenger
Meta's approach demonstrates that the real power of AI coding assistants comes from giving them a map before they start exploring. By encoding tribal knowledge into a self-updating, model-agnostic layer, engineering teams can dramatically improve correctness, efficiency, and speed of AI-assisted development. The pre-compute engine turned an AI from a guessing game into a guided expert, and it continues to refine itself over time.